BPMN Activities, Tasks, Subprozess und Call-Activities
In den vorangegangenen Artikeln haben wir uns angesehen, wie wir den Prozess starten (Events) und wie wir den Weg steuern (Gateways). Das ist das Gerüst. Aber ein Gerüst allein schafft noch keinen Wert. Jetzt widmen wir uns dem eigentlichen Herzstück der Prozessmodellierung: der Arbeit selbst.
In BPMN bezeichnen wir alles, was im Rahmen eines Geschäftsprozesses "getan" wird, als Aktivität (Activity). Eine Aktivität repräsentiert eine Einheit an Arbeit, die ausgeführt wird. Wenn wir bei unserer Analogie einer Reise bleiben, dann sind die Events die Verkehrsschilder und die Gateways die Kreuzungen – aber die Aktivität ist die Fahrt selbst. Es ist der Zeitraum, in dem Ressourcen verbraucht werden und der eigentliche Fortschritt passiert.
Vielleicht kennst du einfache Flussdiagramme, in denen jedes Rechteck gleich aussieht. In der professionellen BPMN-Modellierung reicht das nicht aus. Ein einfaches Rechteck sagt uns zwar, dass etwas getan wird, aber nicht wer es tut oder wie es getan wird. Prüft ein Sachbearbeiter die Rechnung manuell? Oder gleicht ein Server die Daten vollautomatisch im Hintergrund ab?
Für eine saubere Prozessanalyse – und erst recht für die technische Automatisierung – ist dieser Unterschied gigantisch. Deshalb bietet BPMN 2.0 ein präzises Set an Symbolen (Tasks und Marker), mit denen du genau definieren kannst, ob hier ein Mensch schwitzt oder ein Prozessor rechnet.
In diesem Artikel lernst du, wie du die vagen "Kästchen" in präzise Arbeitsanweisungen verwandelst.
Die Hierarchie: Activity vs. Task vs. Subprozess
Bevor wir uns die verschiedenen Symbole für "Mensch" oder "Maschine" ansehen, müssen wir eine begriffliche Hürde nehmen, an der viele Einsteiger scheitern. In der BPMN-Welt werden die Begriffe oft wild durcheinandergeworfen. Was ist der Unterschied zwischen einer Aktivität, einer Aufgabe und einem Teilprozess?
Um saubere Modelle zu bauen, musst du diese Hierarchie verstehen.
1. Activity (Aktivität): Der Oberbegriff
Der Begriff "Aktivität" ist in BPMN der generische Überbegriff1111. Er beschreibt jede Form von Arbeit, die innerhalb eines Geschäftsprozesses verrichtet wird. Wenn du also ein abgerundetes Rechteck in einem Diagramm siehst, ist es technisch gesehen immer eine Aktivität – egal, was genau darin passiert.
Eine Aktivität ist aber noch keine konkrete Form. Sie ist nur die Kategorie. Sie kann entweder atomar (ein Task) oder zusammengesetzt (ein Subprozess) sein.
2. Task (Aufgabe): Der kleinste Baustein
Ein Task ist eine atomare Aktivität. "Atomar" bedeutet in diesem Kontext: Sie wird im Modell nicht weiter zerlegt. Es ist ein einzelner, nicht teilbarer Arbeitsschritt.
Wenn du den Schritt "Rechnung prüfen" modellierst und es für den Prozess irrelevant ist, welche einzelnen Mausklicks der Mitarbeiter dabei macht, dann ist das ein Task. Er hat keine interne Struktur, die im Prozessmodell sichtbar ist. Tasks sind die Bausteine, aus denen wir den Prozess zusammensetzen.
3. Subprozess (Teilprozess): Der Container
Ein Subprozess ist eine zusammengesetzte Aktivität. Das bedeutet, er ist eine Aktivität, die in ihrem Inneren wiederum aus einer Abfolge von kleineren Schritten (Tasks, Gateways, Events) besteht.
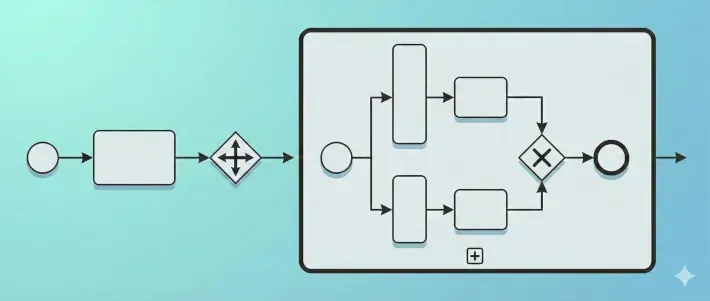
Du erkennst einen Subprozess meistens daran, dass er "zugeklappt" ist (Collapsed Subprocess). Er sieht aus wie ein normaler Task, trägt aber ein kleines Plus-Zeichen (+) am unteren mittleren Rand.
Warum ist das wichtig?
Subprozesse sind dein wichtigstes Werkzeug gegen Komplexität. Sie erlauben dir, Details zu verstecken ("kapseln"). Auf der obersten Ebene zeigst du dem Management vielleicht nur den Schritt "Auftrag abwickeln" als einen Subprozess. Das hält das Diagramm übersichtlich. Wenn ein Entwickler oder Detail-Analyst wissen will, wie das genau funktioniert, "klappt" er den Subprozess auf (in einem separaten Diagramm oder einer vergrößerten Ansicht) und sieht die 20 detaillierten Tasks, die darin verborgen sind.
Die Task-Typen: Wer macht die Arbeit?
In klassischen Flussdiagrammen sehen alle Aufgaben gleich aus – ein Rechteck ist einfach ein Rechteck. In der professionellen BPMN-Modellierung reicht das jedoch nicht aus. Hier unterscheiden wir präzise, wer oder was die Arbeit verrichtet. Diese Unterscheidung ist entscheidend, sobald du Prozesse nicht nur malen, sondern auch analysieren oder automatisieren möchtest. BPMN nutzt dafür kleine Symbole (Icons) in der oberen linken Ecke der Aktivität, um den Typ der Aufgabe zu definieren.
Der Abstrakte Task (None Task)
Die einfachste Form ist der Task ohne Symbol. Wir nennen ihn den abstrakten Task oder „None Task“. Er hat keinen definierten Typ und lässt völlig offen, wer die Arbeit erledigt. In der Praxis eignet er sich hervorragend für die ganz frühe Phase der Prozessaufnahme oder für grobe fachliche Skizzen, in denen es dir egal ist, ob ein Mensch oder eine Maschine den Schritt ausführt. Sobald du jedoch in Richtung IT-Umsetzung oder detaillierte Analyse gehst, ist er eine Sackgasse, da eine Workflow-Engine nicht wissen kann, was sie an dieser Stelle tun soll.
Der Benutzer-Task (User Task)
Wenn ein Mensch in den Prozess eingebunden ist und dabei ein IT-System nutzt, verwendest du den User Task. Du erkennst ihn an dem kleinen Männchen-Symbol oben links. Dies ist in der Prozessautomatisierung der wohl wichtigste Task-Typ. Er signalisiert der Process Engine: „Hier muss die Software anhalten und eine Aufgabe in die Aufgabenliste eines Mitarbeiters legen.“. Der Prozess wartet an dieser Stelle geduldig, bis der Mitarbeiter das Formular geöffnet, die Daten eingegeben und auf „Erledigt“ geklickt hat. Typische Beispiele sind das Prüfen einer Rechnung im ERP-System oder die Eingabe von Kundendaten in ein CRM.
Der Service-Task (Service Task)
Das Gegenstück dazu ist der Service Task, erkennbar am Zahnrad-Symbol. Hier findet eine vollautomatische Systemaufgabe statt, ganz ohne menschliches Zutun. Wenn der Prozess diesen Punkt erreicht, ruft die Engine im Hintergrund eine Schnittstelle auf, berechnet einen Wert oder schreibt Daten in eine Datenbank. Da kein Mensch beteiligt ist, läuft dieser Schritt in der Regel in Millisekunden ab. In modernen Architekturen repräsentiert dieser Task oft den Aufruf eines Web Services oder einer Microservice-Funktion.
Der Manuelle Task (Manual Task)
Es gibt jedoch auch Arbeiten, von denen das IT-System absolut nichts mitbekommt. Dafür nutzt du den manuellen Task, markiert durch ein Hand-Symbol. Dieser Task steht für Tätigkeiten, die physisch und ohne direkte Verbindung zur Workflow-Engine ausgeführt werden, wie etwa das Einräumen eines Pakets ins Regal oder ein persönliches Gespräch mit einem Kunden. Für die IT-Automatisierung ist dieser Task oft unsichtbar oder dient nur als Hinweis, da die Engine nicht automatisch erkennen kann, wann diese Arbeit begonnen oder beendet wurde.
Die technischen Spezialisten: Script & Business Rule
Für fortgeschrittene Szenarien bietet BPMN noch zwei spezialisierte Typen an.
Der Script Task (dargestellt durch eine Schriftrolle) führt technischen Programmcode direkt innerhalb der Process Engine aus. Er wird oft für kleine Datenmanipulationen genutzt, ist aber eher ein Werkzeug für Entwickler als für Prozessanalysten.
Der Business Rule Task (dargestellt durch eine Tabelle) hingegen ist sehr mächtig für die fachliche Modellierung. Er lagert komplexe Entscheidungslogiken aus dem Prozessfluss aus. Statt eine riesige Kette von Gateways zu bauen, um einen Rabatt zu berechnen, rufst du hier eine externe Geschäftsregel (z. B. eine DMN-Entscheidungstabelle) auf, die dir das Ergebnis liefert.
Senden und Empfangen (Tasks vs. Events)
Eine der am häufigsten gestellten Fragen in BPMN-Schulungen lautet: „Ich möchte in meinem Prozess eine E-Mail an den Kunden senden. Nehme ich dafür nun einen Task oder ein Event?“
Die Antwort ist auf den ersten Blick nicht trivial, denn BPMN bietet für die Kommunikation mit der Außenwelt gleich mehrere Wege an, die technisch fast das Gleiche tun, aber semantisch unterschiedliche Nuancen haben.
Die spezialisierten Aufgaben: Send Task und Receive Task
Neben den Standard-Aufgaben bietet BPMN zwei dedizierte Typen für die Kommunikation. Der Send Task, erkennbar am schwarzen Briefumschlag, ist eine Aktivität, die genau einen Zweck hat: Sie sendet aktiv eine Nachricht an einen externen Teilnehmer und ist danach sofort abgeschlossen. Der Prozess hält hier nicht an, sondern feuert die Nachricht ab und läuft weiter.
Das Gegenstück ist der Receive Task mit dem weißen Briefumschlag. Er verhält sich technisch wie ein Stoppschild. Wenn der Prozess an diesem Punkt ankommt, friert die Ausführung ein. Die Software (oder der Mitarbeiter) wartet passiv darauf, dass eine spezifische Nachricht von außen eintrifft. Erst wenn diese Nachricht „gefangen“ wurde, darf der Prozess weitermachen.
Die Gretchenfrage: Task oder Event?
Vielleicht ist dir aufgefallen, dass diese Beschreibung fast identisch mit den Message Throw und Message Catch Events klingt, die wir in einem der vorherigen Artikel besprochen haben. Funktional ist der Unterschied tatsächlich minimal – ein Send Task tut technisch fast dasselbe wie ein Message Throw Event.
Wann solltest du also was nutzen? Die „Method & Style“-Lehre gibt hier eine klare Orientierungshilfe, die auf der Lesart des Diagramms basiert.
Wenn der Zustand im Vordergrund steht, solltest du Events verwenden. Ein Ereignis wie „Rechnung empfangen“ signalisiert dem Leser klar: Hier ist ein Meilenstein erreicht, wir haben eine Information bekommen, auf die wir gewartet haben. Events eignen sich zudem besonders gut, um Nachrichten zu empfangen, während man eigentlich gerade etwas anderes tut (als angeheftetes Boundary Event) – das können Tasks nicht leisten.
Wenn hingegen die Arbeit im Vordergrund steht, sind Tasks die bessere Wahl. Das Senden einer Nachricht ist oft nicht nur ein technischer „Ping“, sondern eine komplexe Tätigkeit. Wenn ein Mitarbeiter erst ein individuelles Angebotsschreiben verfassen, Anhänge zusammenstellen und dann auf „Senden“ klicken muss, ist das Arbeit. Ein Task mit dem Namen „Angebot erstellen und senden“ macht diese Arbeitslast im Diagramm sichtbar, während ein Event sie als bloßen Zeitpunkt verschleiern würde.
Ein Kardinalfehler: Das „Senden“ an den Kollegen
Einen Fehler, den du als Profi unbedingt vermeiden musst, ist der Versuch, Nachrichten innerhalb deines eigenen Prozesses zu versenden. In BPMN sind „Senden“ und „Empfangen“ (sowohl als Task als auch als Event) strikt für die Kommunikation über die Grenzen eines Pools hinweg reserviert – also typischerweise zu einem externen Partner wie einem Kunden oder Lieferanten.
Wenn du eine Aufgabe an einen Kollegen in einer anderen Abteilung weitergibst, der sich aber im gleichen Pool (vielleicht in einer anderen Lane) befindet, ist das keine Nachricht im Sinne von BPMN. Es ist einfach nur der normale Prozessfluss. Der Sequenzfluss leitet die Verantwortung weiter. Du benötigst hier weder einen Send Task noch ein Message Event, denn der "Staffelstab" wird intern einfach weitergereicht.
Loop & Multi-Instance: Wenn Aufgaben sich wiederholen
Bisher sind wir davon ausgegangen, dass eine Aufgabe genau einmal ausgeführt wird, wenn der Prozess dort ankommt. In der Realität ist das oft anders. Manchmal müssen wir eine Tätigkeit so lange wiederholen, bis ein Ergebnis stimmt, oder wir müssen eine ganze Liste von Dingen abarbeiten.
In alten Flussdiagrammen hat man dafür einfach einen Pfeil zurück an den Anfang der Aufgabe gemalt. Das funktioniert zwar, macht Diagramme aber schnell unübersichtlich ("Spaghetti-Diagramme"). BPMN 2.0 bietet eine viel elegantere Lösung: Marker. Das sind kleine Symbole am unteren mittleren Rand der Aktivität, die das Verhalten der Aufgabe grundlegend verändern.
Die Standard-Schleife (Loop)
Das erste wichtige Symbol ist der kleine kreisförmige Pfeil. Er verwandelt eine normale Aufgabe in eine Schleifen-Aktivität (Loop Activity). Das Prinzip dahinter ist vergleichbar mit einer "Do-While"-Schleife in der Programmierung.
Du setzt diesen Marker ein, wenn die Aufgabe wiederholt werden muss, du aber am Anfang noch nicht weißt, wie oft genau. Die Wiederholung hängt von einer Bedingung ab. Ein klassisches Beispiel ist die "Korrektur eines Dokuments". Der Mitarbeiter bearbeitet das Dokument, prüft dann, ob es fertig ist, und wenn nicht, muss er es noch einmal bearbeiten. Das passiert so lange, bis die Bedingung ("Dokument ist fehlerfrei") erfüllt ist. Der Prozess kann hier also theoretisch einmal, zehnmal oder hundertmal durchlaufen, bevor er weitermacht .
Die Mehrfach-Instanz (Multi-Instance)
Viel häufiger wirst du in der Praxis jedoch auf Situationen treffen, in denen du genau weißt, wie oft etwas getan werden muss – nämlich einmal für jedes Element einer Liste. Das nennen wir Mehrfach-Instanz (Multi-Instance). Das Symbol hierfür sind drei Striche.
Stell dir vor, du hast eine Bestellung mit fünf Positionen erhalten und musst die Verfügbarkeit für jede einzelne Position prüfen. Du weißt schon vor Beginn der Arbeit: "Ich muss das fünfmal tun." In diesem Fall wäre eine Standard-Schleife falsch. Stattdessen nutzt du den Multi-Instance-Marker. Er signalisiert der Process Engine (oder dem Leser): "Nimm die Liste der Bestellpositionen und führe diese Aufgabe für jeden Eintrag einmal aus" (wie eine "For-Each"-Schleife).
Hier gibt es eine wichtige Unterscheidung im Detail, die du kennen musst:
Wenn die drei Striche senkrecht stehen (|||), bedeutet das parallele Ausführung. Die fünf Verfügbarkeitsprüfungen können gleichzeitig stattfinden. Das ist der Standard für maximales Tempo.
Wenn die drei Striche waagerecht liegen, bedeutet das sequenzielle Ausführung. Die Positionen werden nacheinander abgearbeitet – erst Position 1, dann Position 2. Das ist wichtig, wenn die Reihenfolge eine Rolle spielt.
Die Entscheidungshilfe
Wann nimmst du also was? Die "Method & Style"-Regel ist simpel: Frage dich, ob du die Anzahl der Wiederholungen vorher berechnen kannst.
Hast du eine Liste oder eine feste Menge (z. B. "Alle Mitarbeiter der Abteilung")? Dann ist es eine Multi-Instance.
Hängt die Wiederholung vom Ergebnis der Arbeit selbst ab (z. B. "Solange Fehler gefunden werden")? Dann ist es ein Loop.
BPMN Subprozesse & Call Activities: So beherrschst du die Komplexität
Kennst du das Problem? Du fängst an, einen Prozess zu modellieren, und je mehr Details du hinzufügst, desto größer wird das Diagramm. Irgendwann passt es nicht mehr auf einen Bildschirm, geschweige denn auf ein A4-Blatt. Du hast ein riesiges Monster erschaffen, dem niemand mehr folgen kann.
In der Softwareentwicklung hat man dieses Problem schon vor Jahrzehnten gelöst: Man zerlegt große Programme in kleine, handhabbare Module. Genau dieses Prinzip bringt BPMN 2.0 in die Welt der Prozesse. Wir nutzen dafür zwei mächtige Werkzeuge: den Subprozess (Subprocess) und die Call Activity (Aufruf-Aktivität).
Beide sehen auf den ersten Blick ähnlich aus – wie Aktivitäten, die andere Aktivitäten enthalten. Doch technisch und methodisch gibt es einen gigantischen Unterschied, der über die Wartbarkeit deiner Prozesslandschaft entscheidet. In diesem Artikel lernst du, wie du Schachteln baust, um deine Diagramme sauber und lesbar zu halten.
Der eingebettete Subprozess (Embedded Subprocess)
Der Subprozess ist dein wichtigstes Werkzeug, um Details zu verstecken. Stell dir vor, du modellierst einen Beschaffungsprozess. Ein Schritt darin heißt "Angebote einholen". Fachlich ist das vielleicht nur ein Schritt auf der obersten Ebene. Aber wenn wir hineinzoomen, besteht dieser Schritt eigentlich aus "Lieferanten anschreiben", "Warten", "Vergleichen" und "Auswählen".
Anstatt diese vier Schritte direkt in das Hauptdiagramm zu malen und es damit aufzublähen, kapselst du sie in einem Subprozess.
Das Symbol und die Darstellung
Du erkennst einen Subprozess an einem abgerundeten Rechteck, das meistens ein kleines Plus-Zeichen (+) am unteren Rand trägt. Das bedeutet: "Hier ist etwas zugeklappt" (Collapsed Subprocess). Das Diagramm bleibt übersichtlich. Wenn der Leser wissen will, was genau passiert, kann er den Subprozess "aufklappen" (Expanded Subprocess) oder auf eine verlinkte Detailseite springen .
Die goldene Regel für den Start
Es gibt eine technische Regel, die du unbedingt beachten musst: Ein normaler eingebetteter Subprozess wird nicht durch eine Nachricht oder einen Timer gestartet. Er startet genau dann, wenn der Sequenzfluss des übergeordneten Prozesses (Parent Process) bei ihm ankommt.
Deshalb darf ein Subprozess im Inneren niemals ein Start-Ereignis mit einem Symbol (wie Briefumschlag oder Uhr) haben. Er muss zwingend mit einem unbestimmten Start-Ereignis (None Start Event) beginnen . Der Fluss "fällt" sozusagen von oben in den Subprozess hinein, läuft durch und kommt am Ende wieder heraus.
Die Daten-Sicht
Ein eingebetteter Subprozess ist fest mit seinem Elternprozess verwachsen. Er ist wie ein Kind, das im selben Haus wohnt. Das bedeutet technisch oft, dass er Zugriff auf alle Datenvariablen des Elternprozesses hat. Du musst Daten nicht zwingend aufwendig übergeben, da der Subprozess den Kontext "kennt".
Die Call Activity (Der globale Prozess)
Was aber, wenn du einen Prozessschritt hast, der nicht nur in einem Prozess vorkommt, sondern in vielen? Nehmen wir das Beispiel "Prüfe Bonität". Das brauchen wir im Vertriebsprozess, im Leasing-Prozess und bei der Neukundenanlage.
Würdest du das jedes Mal als Subprozess neu modellieren, hättest du das gleiche Modell an fünf Stellen kopiert. Wenn sich die Prüfung ändert, müsstest du fünf Diagramme anpassen. Das ist ineffizient und fehleranfällig. Die Lösung ist die Call Activity (Aufruf-Aktivität).
Das Prinzip der Wiederverwendung
Eine Call Activity ist im Grunde nur ein Link. Sie sagt der Process Engine: "Bitte führe an dieser Stelle den Prozess 'Prüfe Bonität' aus, der in einer ganz anderen Datei gespeichert ist." Wir rufen einen Globalen Prozess (Global Process) oder Global Task auf .
Du erkennst eine Call Activity in vielen Tools an einem dicken Rand (Thick Border). Sie ist der Hinweis darauf, dass wir hier ein Modul wiederverwenden, das zentral gepflegt wird.
Die strenge Datenübergabe
Im Gegensatz zum eingebetteten Subprozess ist der aufgerufene Prozess unabhängig. Er kennt den Elternprozess nicht. Er weiß nicht, wer ihn aufruft. Deshalb hat er auch keinen Zugriff auf die Daten des Elternprozesses.
Wenn du eine Call Activity nutzt, musst du den Datenaustausch explizit definieren:
Input: Welche Daten übergebe ich an den Prozess? (z. B. Kunden-ID).
Output: Was bekomme ich zurück? (z. B. Score-Wert).
Das macht die Modellierung etwas aufwendiger, sorgt aber für saubere Schnittstellen und echte Wiederverwendbarkeit .
Method & Style: Hierarchisch modellieren
Bruce Silver, der Papst der BPMN-Methodik, empfiehlt dringend den Ansatz der hierarchischen Modellierung (Top-Down Modeling). Das bedeutet: Du startest nicht mit den Details. Du startest mit der Vogelperspektive .
Level 1: Der End-to-End Überblick
Dein oberstes Diagramm sollte auf eine einzige Seite passen (ca. 5-10 Schritte). Es zeigt die groben Phasen des Prozesses. Jeder dieser Schritte ist ein kollabierter Subprozess. Der Betrachter versteht sofort den großen Zusammenhang: "Ah, erst erfassen wir, dann prüfen wir, dann liefern wir."
Level 2: Der Drill-Down
Wenn du nun wissen willst, wie "Prüfen" funktioniert, klickst du auf den Subprozess und öffnest ein neues Diagramm (Child Level Diagram). Dort modellierst du die Details.
Warum "Inline-Expansion" oft schlecht ist
Manche Tools erlauben es, Subprozesse direkt im Hauptdiagramm aufzuklappen ("Inline Expansion"). Das vergrößert die Box und schiebt alles andere zur Seite. Method & Style rät davon ab. Es zerreißt das Layout und macht den übergeordneten Fluss unleserlich. Besser ist es, den Subprozess als geschlossene Box zu lassen und die Details auf einem separaten Blatt oder in einer verlinkten Ansicht zu modellieren. So bleibt dein Modell sauber und verständlich
Fazit: Wann nutze ich was?
Die Entscheidung zwischen Subprozess und Call Activity ist eine Architekturentscheidung. Hier ist deine Entscheidungshilfe:
Nutze einen Eingebetteten Subprozess, wenn:
Der Ablauf spezifisch nur für diesen einen übergeordneten Prozess ist.
Du einfach nur aufräumen und Details verstecken willst.
Du vollen Zugriff auf alle Prozessdaten brauchst.
Nutze eine Call Activity, wenn:
Der Ablauf in mehreren verschiedenen Prozessen identisch vorkommt (Wiederverwendung).
Der Teilprozess von einem anderen Team verantwortet und gepflegt wird.
Du strikte Schnittstellen (Input/Output) definieren willst.
Dein Experte
Oliver Berndorf
Lead Business Analyst, Projektmanager und Dozent
Als Lead Business Analyst in einer Unternehmensberatung optimiere ich die komplexen Landschaften globaler Konzerne (Global Players).
Mein Ansatz geht über reine Prozesse hinaus: Ich verknüpfe BPMN mit Entscheidungslogik (DMN) und Systemarchitektur (SysML), um nachhaltige Lösungen zu schaffen.
Hier teile ich meine Praxiserfahrung aus über 20 Jahren, damit du diese Standards nicht nur theoretisch verstehst, sondern im Projektalltag erfolgreich kombinierst.